Cesium ion Cloud Architecture
Hot on the heels of last week’s Cesium ion announcement, we wanted to provide a high-level overview of the ion cloud architecture that will tile 3D content and stream it to hundreds of millions of users.
From humble beginnings as a few hundred lines of Node.js code, ion has matured into a docker-based, multi-server platform that makes heavy use of AWS while being modular for local hosting as an on-premises solution.
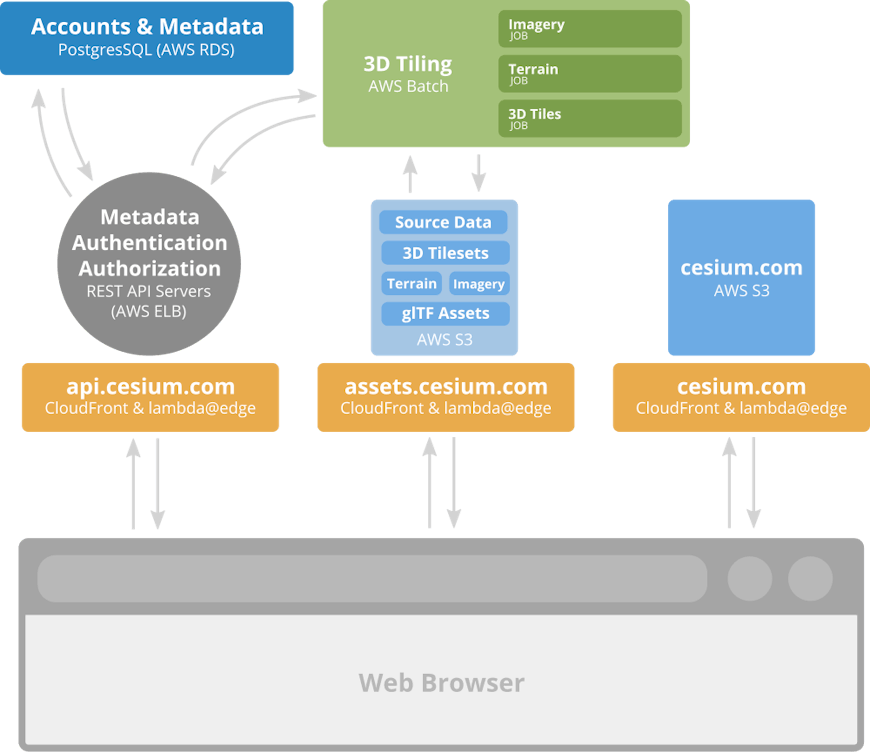
A million mile high view of the ion architecture.
From an end user’s perspective, the architecture consists of three major components:
- assets.cesium.com - Stores user-uploaded source data and serves 3D tilesets, imagery, terrain, glTF, KML, and CZML (all of which we collectively refer to as assets).
- api.cesium.com - Home of the ion REST API. Used for account and asset management, initiates the tiling pipeline, and will eventualy provide geocoding, server-based analysis, and anything else our users need to create robust 3D mapping applications.
- cesium.com/ion - The ion single page application (SPA) for uploading and managing 3D content, accessing curated content such as Cesium World Terrain, and (eventually) performing interactive map making and geospatial analysis.
3D tiling
The most critical feature of Cesium ion is our tiling pipeline. We need automated, robust, efficient tiling of heterogenous data, such as imagery, terrain, point clouds, photogrammetry, BIM, and more. This presents some unique challenges since the source data is quite varied and the amount of computational power needed is highly dependent on the input. We also want a system that can scale seamlessly as more users take advantage of it without resorting to a queue-based approach that places users in a virtual line while they wait for their data to be processed. Finally, we want each tiling job to run in isolation to avoid any chance of cross-user data contamination. Thankfully, our use case is a perfect fit for AWS Batch.
Batch scales horizontally, allows us to customize how much processing and RAM we need on a per-job basis, and uses Docker images (which we were already generating) to execute. The end result is a processing pipeline capable of dealing with thousands of simultaneous tiling requests while letting us efficiently manage operating costs. The use of per-job Docker images creates a micro-service-like architecture that allows us to improve our tilers without having to update and redeploy the entire server.
Asset hosting
Assets can get pretty big pretty fast. The Cesium World Terrain and Sentinel-2 tilesets alone are several hundred million tiles. As ion matures, we expect billions (if not trillions) of tiles to be generated. It’s not ideal to store or serve this type of data with a database (we know because we tried). Instead, Batch jobs both pull source data from and store generated assets back onto Amazon S3 where it can be served as a static “pile of files” behind the CloudFront CDN. Not only does CloudFront allow us to cache data at edge locations all over the world, but leveraging lambda@edge allows us go serverless while still providing token-based authorization (we use JSON Web Tokens) and lightweight on-the-fly data processing. For example, we create quantized-mesh terrain tiles based on desired extensions requested in an Accept header. Having our assets hosted via CloudFront provides global, practically infinite scalability.
REST API server
While the tiling pipeline and asset hosting lives on the cutting edge, our REST API server is much more traditional. We use a Node.js-based restify server that provides endpoints for managing accounts and assets, subscribing to curated assets available in our Asset Depot, and requesting access tokens to data on assets.cesium.com. All data managed by the API server is stored in PostgreSQL, and we use Knex.js as our database client. The server (or more specifically bank of servers) is hosted via Elastic Beanstalk and managed by an Elastic Load Balancer.
This solution is a good fit for us for the time being, since we’re concentrating on 3D tiling and asset serving. Looking ahead, as our REST API grows and begins to add additional features, such as geocoding or server-side analysis, we have plans to move to a Kubernetes-based solution. Kubernetes is better suited for the micro-services architecture we have in mind for the long term and has an added benefit of allowing for more robust on-premises deployments.
ion SPA
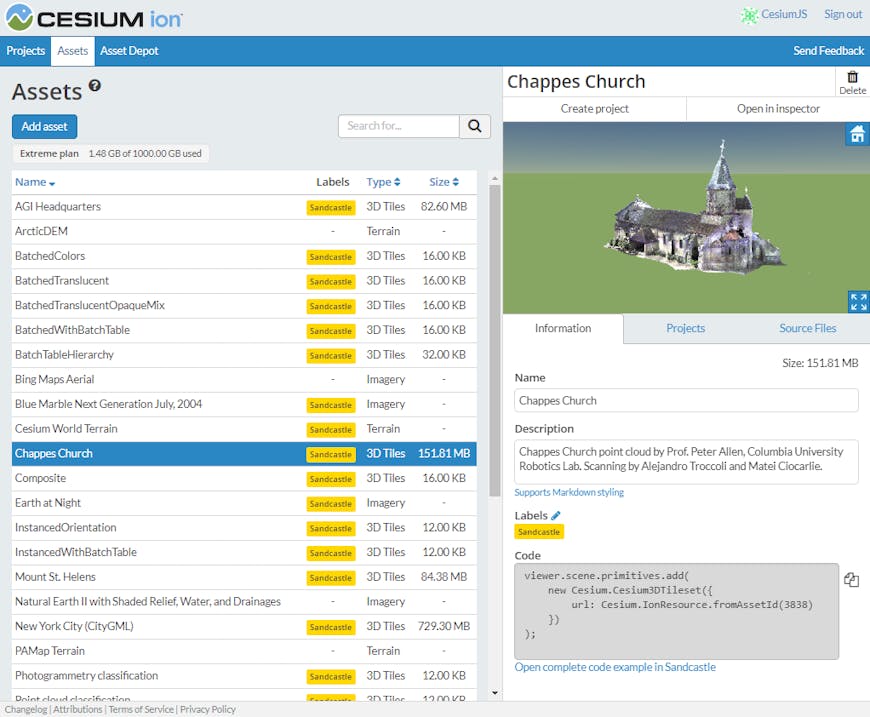
ion assets dashboard.
The SPA does not rely on server-side rendering of HTML. It is just a pile of files that leans on api.cesium.com for services. You’ve probably already guessed that this means our entire front-end is also hosted out of S3 using CloudFront. In this case, it’s actually served alongside cesium.com, which is a Jekyll-generated static site.
Tying it all together
Using the architecture described above, we can trace how source data sitting on a user’s computer gets uploaded, tiled, and displayed in Cesium.
- A user logs into Cesium ion.
- A user uploads one or more files to ion for processing.
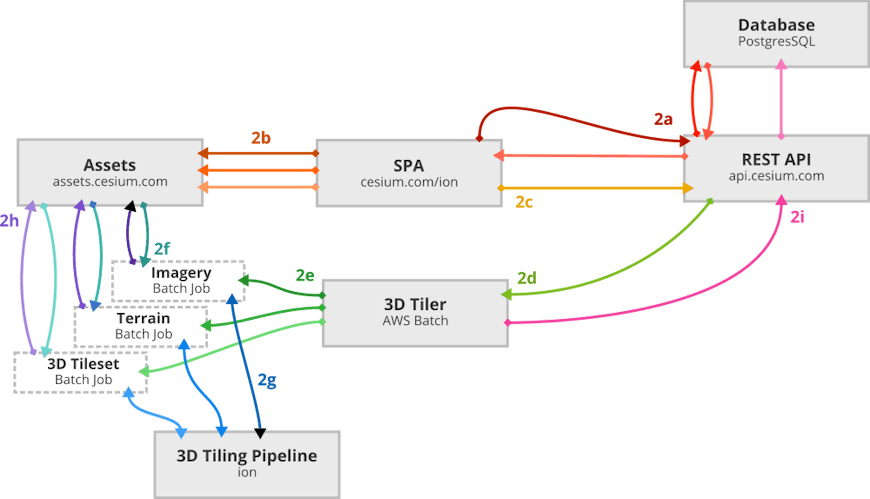
- The upload is initiated by the ion SPA via the REST API server, which creates a new asset in the database that corresponds to a specific type of data (terrain, imagery, 3D Tiles, etc..) and returns temporary credentials for uploading to assets.cesium.com.
- The SPA uploads data directly to assets.cesium.com as an S3 multi-part upload. This scales with S3 and provides parrallel, efficient uploading that can easily handle gigabytes a minute.
- When the upload is complete, the client notifies the REST API.
- The REST API server initiates an AWS Batch job to tile the data.
- Batch retrieves the docker image that corresponds to the correct job for the type of asset being processed from the Amazon Elastic Container Registry.
- The job retrieves the source data from S3.
- The ion 3D tiling pipeline is used to generate a tileset.
- The processed data is stored at its final location back onto S3.
- The asset is marked as complete in the PostgreSQL database, making it available for use on the client.
- The client is notified that the asset is complete.
undefinedundefinedundefined - The asset is now ready for use in CesiumJS or any visualization library that supports the open formats served by ion.
Depending on the size of the data, the above process can take anywhere from a few seconds to a few minutes (or in extreme “Big Data” cases, a few hours). Here’s a realtime video of tiling drone-collected raster imagery of Cesium headquarters.
What’s next?
Sign up at cesium.com to get ready for the May 1 ion release and keep an eye on the blog for more updates!