Using Quantization with 3D Models
The WEB3D_quantized_attributes extension to glTF offers reasonable compression with little to no overhead for decompression. This meets the needs of 3D Tiles in Cesium perfectly because the 3D Tiles engine frequently downloads new tiles based on the view. Quantized 3D model files means smaller files, faster downloads, and less GPU memory usage with no performance degradation.
All about Quantization
The WEB3D_quantized_attributes extension is based on Mesh Geometry Compression for Mobile Graphics, by Jongseok Lee, et al.
Usually model attributes such as positions and normals are stored as 32-bit floating-point numbers. Quantization takes those attributes and stores them as 16-bit integers represented on a scale between the minimum and maximum values. This means that the attribute data can be stored in half the amount of space!
The decompression is done by a simple matrix multiplication in parallel in the vertex shader on the GPU.
Model Quantization in Cesium
Quantization works best on models whose file size is composed mostly of quantizable attributes, such as positions and normals. So files that have complex geometry tend to benefit the most.
To illustrate this, I’ve included a synopsis using two models in the glTF sample models repository.
2 Cylinder Engine
A geometry-heavy model donated to the glTF sample models repository by Okino Polytrans Software.
Statistics
| Image | Original | Quantized | Compression |
|---|---|---|---|
| File Size (Raw) | 1,872 KB | 1,222 KB | 34.7% |
| File Size (gzip) | 590 KB | 502 KB | 14.92% |
| Original | Quantized | Compression | |
|---|---|---|---|
| glTF JSON (.gltf) | 116 KB | 120 KB | -3.44% |
| Binary Data (.bin) | 1,753 KB | 1,099 KB | 37.31% |
| Shaders (.glsl) | 3 KB | 3 KB | 0% |
| Total | 1,872 KB | 1,222 KB | 34.72% |

Original

Quantized
Cesium Milk Truck
A texture-heavy model donated to the glTF sample models repository by the Cesium team.
Statistics
| Image | Original | Quantized | Compression |
|---|---|---|---|
| File Size (Raw) | 1,036 KB | 988 KB | 4.63% |
| File Size (gzip) | 926 KB | 919 KB | 0.76% |
| Original | Quantized | Compression | |
|---|---|---|---|
| glTF JSON (.gltf) | 19 KB | 18 KB | 5.26% |
| Binary Data (.bin) | 111 KB | 64 KB | 42.34% |
| Shaders (.glsl) | 4 KB | 4 KB | 0% |
| Textured Images | 902 KB | 902 KB | 0% |
| Total | 1,036 KB | 988 KB | 4.63% |

Original

Quantized
As expected, the model with more geometry benefits more from this compression, but even the model whose file size is mostly impacted by texture benefits from what is effectively free compression.
The reason the data doesn’t shrink down all the way to 50% is because a portion of the binary data buffer is made up of indices that cannot be quantized.
Applying gzip to models shrinks the gap between the quantized and non-quantized file sizes, but ultimately the quantized models still have a size advantage over their non-quantized counterparts and use less GPU memory.
There are some slight changes in the size of the glTF JSON itself. This is due to restructuring of the data accessors during quantization as well as the addition of a few properties enabling quantization. These steps are a result of the gltf-pipeline implementation.
The gltf-pipeline project contains an open-source implementation of quantization that can be used to compress your glTF models.
Compatibility with Existing Compression
We already use two techniques for compressing normal and texture coordinate attributes in Cesium. Normal vectors are oct-encoded using the technique described in A Survey of Efficient Representations of Independent Unit Vectors, by Zina H. Cigolle, et al. This compresses three 32-bit floating-point numbers down to two bytes, a roughly 83% compression, so this approach is preferable to quantization of normals.
The other technique stores two 32-bit floating-point numbers representing texture coordinates into a single 32-bit floating-point number. Like quantization, this also results in roughly 50% compression, so either technique can be used with similar results.
Unfortunately, quantization cannot be used to further compress these attributes. It can only be applied to floating-point attributes so it cannot be used on the byte oct-encoded normals, and even though the texture coordinate compression does store its value into a float, attempting to apply quantization on top of it produces some interesting results.

This is what happens when you try to quantize already-compressed texture coordinates.
This happens for two reasons: the first is that quantization is a lossy compression; the second is that compressed texture coordinates are not necessarily mapped linearly. Quantization will produce a decompressed value close to the original, but it won’t necessarily be the same value [A].
Thus our approach is to quantize positions, oct-encode normals, and either quantize or compress texture coordinates [B].
The statistics for oct-encoding normals and quantizing attributes for the 2 Cylinder Engine model are shown below.
Statistics
| Image | Original | Quantized | Compression |
|---|---|---|---|
| File Size (Raw) | 1,872 KB | 988 KB | 47.22% |
| File Size (gzip) | 590 KB | 457 KB | 22.54% |
| Original | Quantized | Compression | |
|---|---|---|---|
| glTF JSON (.gltf) | 116 KB | 102 KB | 12.07% |
| Binary Data (.bin) | 1,753 KB | 881 KB | 49.74% |
| Shaders (.glsl) | 3 KB | 5 KB | -40% |
| Total | 1,872 KB | 988 KB | 47.22% |
Original
Quantized
The shader modification required for oct encoding normals does increase the size of the shaders, but it isn’t much compared to the size of the model as a whole.
Model Quantization in 3D Tiles
3D Tiles is an open format for streaming massive heterogeneous 3D geospatial datasets.
With support for quantized attributes in Cesium, the glTF in the Batched 3D Model (b3dm) and Instanced 3D Model (i3dm) tile formats can be quantized for faster downloads and less GPU memory usage with no performance hits.
The data used in the benchmarks and screenshots below is from CyberCity 3D’s Washington DC data set. The zoom benchmark is an average of the frames per second while zooming into the city, causing additional tiles to be loaded, as shown below.
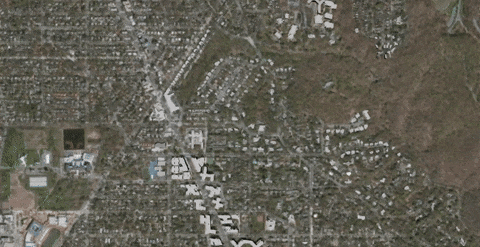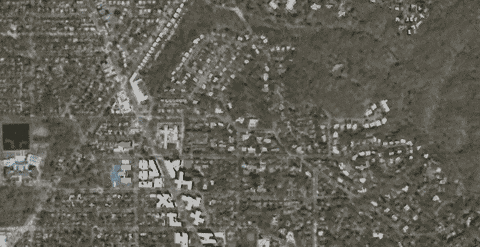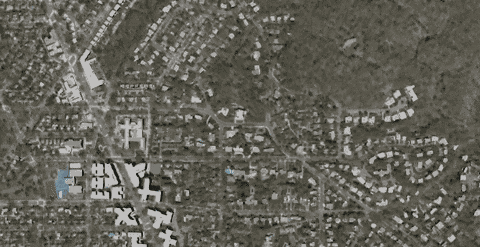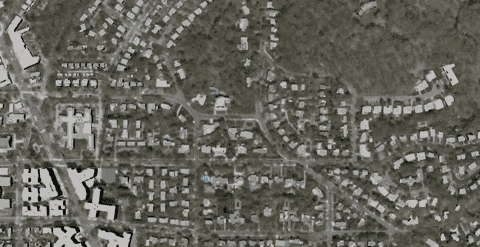
The models used here already have their normals oct-encoded, so the compression represents the gain from quantizing only the positions of the models.
Northwest Cleveland Park
The table below shows the file size breakdowns and compression statistics for the batched 3D model of Northwest Cleveland Park in Washington, D.C. The files are broken up into level-of-detail hierarchies.
Statistics

Original

Quantized
| File Size (raw) | Total | 5.92 MB | 5.29 MB | 10.64% |
|---|---|---|---|---|
| Average | 328 KB | 294 KB | 10.37% | |
| 0/0/0.b3dm | 164 KB | 123 KB | 25.00% | |
| 1/0/0.b3dm | 279 KB | 232 KB | 16.85% | |
| 1/0/1.b3dm | 428 KB | 378 KB | 11.68% | |
| 1/1/0.b3dm | 278 KB | 222 KB | 20.14% | |
| 1/1/1.b3dm | 556 KB | 499 KB | 10.25% | |
| 2/0/0.b3dm | 365 KB | 348 KB | 4.66% | |
| 2/0/1.b3dm | 287 KB | 261 KB | 9.06% | |
| 2/0/2.b3dm | 205 KB | 191 KB | 6.82% | |
| 2/1/0.b3dm | 315 KB | 293 KB | 6.98% | |
| 2/1/1.b3dm | 334 KB | 306 KB | 8.38% | |
| 2/1/2.b3dm | 268 KB | 249 KB | 7.09% | |
| 2/1/3.b3dm | 207 KB | 196 KB | 5.31% | |
| 2/2/0.b3dm | 436 KB | 385 KB | 11.69% | |
| 2/2/1.b3dm | 431 KB | 378 KB | 12.30% | |
| 2/2/2.b3dm | 227 KB | 205 KB | 9.69% | |
| 2/3/0.b3dm | 425 KB | 376 KB | 11.53% | |
| 2/3/1.b3dm | 369 KB | 323 KB | 12.47% | |
| 2/3/3.b3dm | 346 KB | 327 KB | 5.49% |
| Image | Original | Quantized | Compression | |
|---|---|---|---|---|
| File Size (Raw) | Total | 5.92 MB | 5.29 MB | 10.64% |
| Average | 328 KB | 294 KB | 10.37% | |
| 0/0/0.b3dm | 164 KB | 123 KB | 25.00% | |
| 1/0/0.b3dm | 279 KB | 232 KB | 16.85% | |
| 1/0/1.b3dm | 428 KB | 378 KB | 11.68% | |
| 1/1/0.b3dm | 278 KB | 222 KB | 20.14% | |
| 1/1/1.b3dm | 556 KB | 499 KB | 10.25% | |
| 2/0/0.b3dm | 365 KB | 348 KB | 4.66% | |
| 2/0/1.b3dm | 287 KB | 261 KB | 9.06% | |
| 2/0/2.b3dm | 205 KB | 191 KB | 6.82% | |
| 2/1/0.b3dm | 315 KB | 293 KB | 6.98% | |
| 2/1/1.b3dm | 334 KB | 306 KB | 8.38% | |
| 2/1/2.b3dm | 268 KB | 249 KB | 7.09% | |
| 2/1/3.b3dm | 207 KB | 196 KB | 5.31% | |
| 2/2/0.b3dm | 436 KB | 385 KB | 11.69% | |
| 2/2/1.b3dm | 431 KB | 378 KB | 12.30% | |
| 2/2/2.b3dm | 227 KB | 205 KB | 9.69% | |
| 2/3/0.b3dm | 425 KB | 376 KB | 11.53% | |
| 2/3/1.b3dm | 369 KB | 323 KB | 12.47% | |
| 2/3/3.b3dm | 346 KB | 327 KB | 5.49% | |
| Total | 1.32 | 1.22 MB | 7.58% |
| Image | Original | Quantized | Compression | |
|---|---|---|---|---|
| File Size (gzip) | Total | 1.32 MB | 1.22 MB | Compression |
| Average | 73.56 KB | 67.72 KB | 7.94% | |
| 0/0/0.b3dm | 49 KB | 42 KB | 14.29% | |
| 1/0/0.b3dm | 68 KB | 61 KB | 10.29% | |
| 1/0/1.b3dm | 97 KB | 88 KB | 9.28% | |
| 1/1/0.b3dm | 70 KB | 61 KB | 12.86% | |
| 1/1/1.b3dm | 124 KB | 114 KB | 8.06% | |
| 2/0/0.b3dm | 76 KB | 73 KB | 3.95% | |
| 2/0/1.b3dm | 63 KB | 58 KB | 7.94% | |
| 2/0/2.b3dm | 46 KB | 43 KB | 6.52% | |
| 2/1/0.b3dm | 67 KB | 63 KB | 5.97% | |
| 2/1/1.b3dm | 71 KB | 67 KB | 5.63% | |
| 2/1/2.b3dm | 59 KB | 55 KB | 6.78% | |
| 2/1/3.b3dm | 45 KB | 43 KB | 4.44% | |
| 2/2/0.b3dm | 96 KB | 88 KB | 8.33% | |
| 2/2/1.b3dm | 95 KB | 87 KB | 8.42% | |
| 2/2/2.b3dm | 52 KB | 48 KB | 7.69% | |
| 2/3/0.b3dm | 94 KB | 86 KB | 8.51% | |
| 2/3/1.b3dm | 81 KB | 74 KB | 8.64% | |
| 2/3/3.b3dm | 71KB | 68 KB | 4.23% |
The zoom benchmark averaged ~52 FPS over 10 seconds for both quantized and non-quantized data sets running in Chrome 51.0.2704.84 on Windows (Intel® Core™ i7-4980HQ Quad-Core @2.80GHz and AMD Radeon R9 M370X).
Entire Washington, D.C. Data Set
The whole Washington D.C. data set was quantized in this run. For brevity’s sake, I’m not going to include the level-of-detail hierarchy breakdown, just the overall statistics.
Statistics
| Image | Original | Quantized | Compression |
|---|---|---|---|
| File Size (Raw) | 367 MB | 318 MB | 13.35% |
| File Size (gzip) | 85.5 MB | 75.4 MB | 11.81% |
The zoom benchmark averaged ~50 FPS over 10 seconds for both quantized and non-quantized data sets.
So, as with the individual models, applying the gzip does bring the quantized and non-quantized file sizes closer, but the city datasets still see a solid ~10% drop in file size and reduced GPU memory usage. Building models with more complex geometry appear to benefit more from the compression.
This can be confirmed by looking at the Northwest Cleveland Park tiles. 0/0/0.b3dm compressed the most, while 2/0/0.b3dm compressed the least.
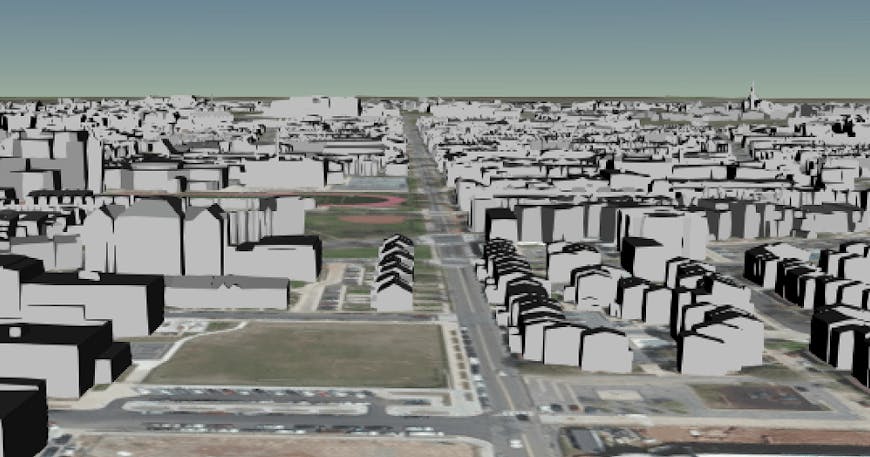
0/0/0.b3dm
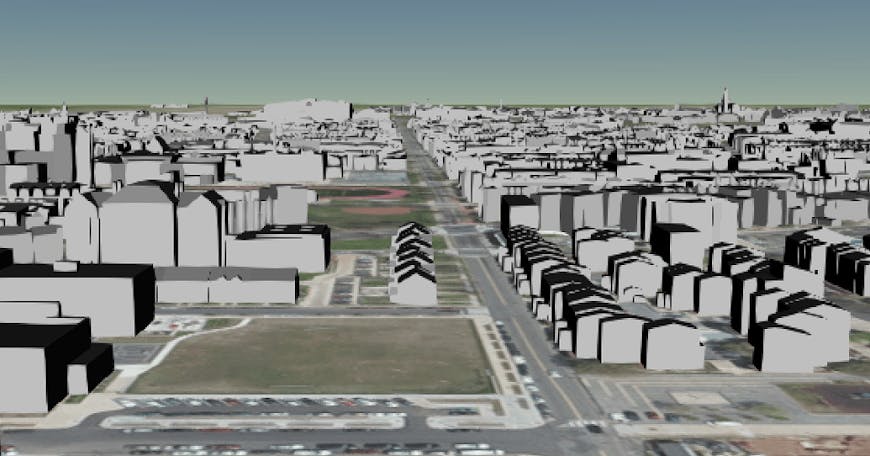
2/0/0.b3dm
2/0/0.b3dm is a neighborhood with very simple house models, while 0/0/0.b3dm has buildings with more complex geometry.
The b3dm tiles include an additional field not found in normal glTF, a per-attribute uint16 Batch ID used to uniquely identify each building, which cannot be quantized and does contribute to the overall file size.
Conclusions
This is a very promising addition to glTF and to Cesium’s implementation of 3D Tiles. The zooming benchmark was unhindered by the quantization, and in the renderings there is visually no difference. A 10% drop in file size for some of these large city datasets will be a welcome addition to the growing Cesium and 3D Tiles community.
The Cesium implementation of glTF WEB3D_quantized attributes can be found in Model.js in the Cesium GitHub repo.
For the Interested Reader
A. Quantizing Compressed Texture Coordinates
This is the texture coordinate compression algorithm we use in Cesium:
var x = textureCoordinates.x === 1.0 ? 4095.0 : (textureCoordinates.x * 4096.0) | 0;
var y = textureCoordinates.y === 1.0 ? 4095.0 : (textureCoordinates.y * 4096.0) | 0;
return 4096.0 * x + y
Quantization decodes to values close to the original, but not necessarily ones that are exactly the same. The trouble here is that compressed texture coordinates that are numerically close are not necessarily close spatially once they get decompressed. This creates the distortions shown above.
B. Trade-offs between Quantization and Texture Coordinate Compression
Quantization and texture coordinate compression ideally result in 50% compression. So which one is better?
That ends up being a tough question to answer. They are both decoded by fairly simple GPU operations, so the decode performance should be a moot point. What about precision?
Compression will always preserve 12 bits of precision. The current quantization implementation doesn’t do any chunking (splitting up the model into multiple quantized parts to keep precision high), so the precision is dependent on the area being quantized.
If the texture coordinates cover a single square unit, quantization preserves 16 bits of precision and is superior to compression. At 256 square units they break even at 12 bits of precision, and if the texture coordinates cover a larger area than that, compression takes the lead in precision.
In reality, either is probably fine for most use cases.