Draco Compressed Meshes with glTF and 3D Tiles
Draco is a glTF extension for mesh compression along with an open-source library developed by Google to compress and decompress 3D meshes to significantly reduce the size of 3D content. It compresses vertex positions, normals, colors, texture coordinates, and any other generic vertex attributes, improving the efficiency and speed of transmitting 3D content over the web.
This means smaller file sizes and faster streaming, particularly in the case of 3D Tiles, which frequently streams new glTF models when new tiles come into view or a new level of detail is required.
We have been collaborating with Khronos and Google to make Draco a glTF extension, and you can now load Draco compressed models and 3D tilesets in Cesium!

Khronos glTF Draco compression extension
glTF now has the KHR_draco_mesh_compression extension, which enables loading buffers containing Draco compressed geometry. Starting with Cesium 1.44, we support loading glTF assets with Draco compressed data by leveraging Google’s open-source JavaScript decompression library.
Using compressed meshes reduces the resulting file size of a glTF model, meaning these assets take up less space, download less data, and stream faster. To illustrate the difference, we compressed the following files using the Draco encoder, with the default compression level of 7 for all attributes.
Here’s the glTF 2.0 Draco Compressed Cesium Milk Truck sample model compared to the glTF 2.0 Cesium Milk Truck sample model, both of which contain textures as well as animations.
| Draco Compressed | Uncompressed | File |
|---|---|---|
| 2.1 KB | 2.2 KB | CesiumMilkTruck.gltf |
| 14.0 KB | 107 KB | 0.bin |
| 418 KB | 418 KB | CesiumMilkTruck.png |

Draco Compressed

Uncompressed
Since the extension only compresses geometry, the texture payload (CesiumMilkTruck.png) remains the same size (418 KB). The additional JSON metadata created with the extension has little impact on the .gltf file (2.1 KB vs. 2.2 KB).
Next, here’s the glTF 2.0 Draco Compressed Buggy sample model compared to the glTF 2.0 Buggy sample model, which is a mesh with more complex geometry.
| Draco Compressed | Uncompressed | |
|---|---|---|
| 824 KB | 391 KB | Buggy.gltf |
| 0.824 MB | 7.6 MB | Buggy0.bin |

Draco Compressed

Uncompressed
We see a smaller .gltf file (824 KB vs. 391 KB) since less JSON metadata is required to be specified per primitive, as well as a significantly smaller .bin file due to the large amount of geometry that can be compressed using the extension.
Cesium 3D Tiles
When using 3D Tiles, Cesium frequently makes requests and streams new 3D content. Now each tile’s glTF content can be compressed using the Draco extension and streamed faster using less data. Below, we’ve processed 12.8 GB of City GML data containing 1.1 million New York City buildings into a 3D tileset using glTF 2.0 with a Draco compression level of 5.
| Total tileset size | |
|---|---|
| glTF 2.0 with Gzip compression | 738 MB |
| glTF 2.0 with Draco compression | 179 MB |
| glTF 2.0 with Draco and Gzip compression | 149 MB |
In terms of loading times, while we take a small initial hit when performing the overhead of loading and compiling the Draco module Web Assembly, afterwards all tiles stream and decompress more quickly than they would without Draco compression. Here’s a comparison of total loading times of a tileset using glTF 2.0 with only gzip compression vs. glTF 2.0 with Draco compressed and gzip. *

glTF 2.0 (gzipped)

glTF 2.0 with Draco Compression (gzipped)
| glTF 2.0 (gzipped) | glTF 2.0 with Draco Compression (gzipped) |
|---|---|
| Tileset size: 738 MB | Tileset size: 149 MB |
| Load time: 18.921 seconds | Load time: 10.548 seconds |
*Images are sped up at 2x speed for demonstration.
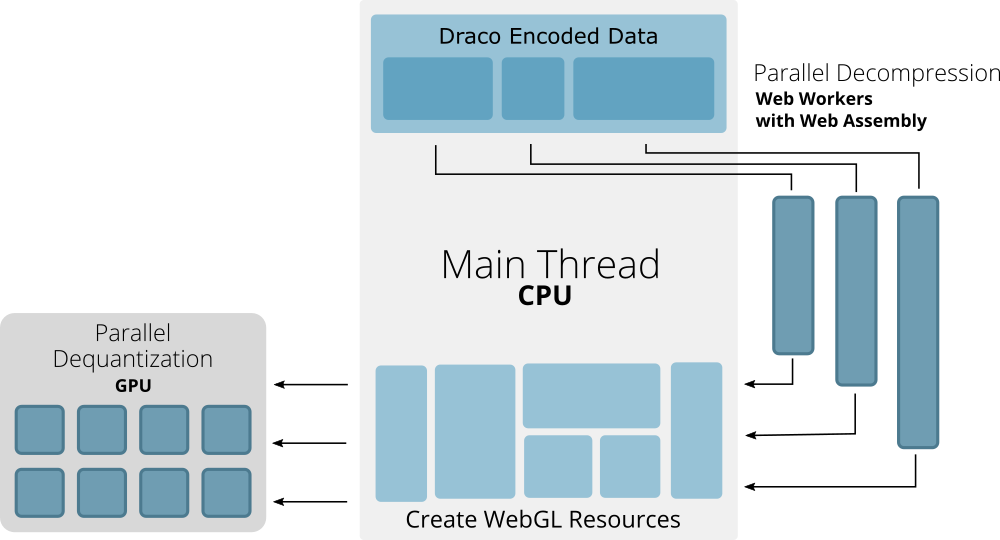
Parallel Decompression
Cesium takes advantage of Web Workers to decode multiple meshes in parallel. In the case of 3D Tiles, this means multiples tiles can be streamed and decoded simultaneously. Furthermore, each primitive (or part) of a mesh can be decoded separately for faster decoding of complex models. We can retrieve each segment of the encoded buffer and pass the data to separate workers to asynchronously decode in parallel before returning the data necessary to render the mesh to the main thread.
When supported by the browser, we load and compile the decoding module Web Assembly binary and share it across multiple workers, further increasing the speed of decompression as opposed to using a pure JavaScript solution.
Dequantization on the GPU
Cesium also decodes some attributes on the GPU, decoding outside of the main thread and using less memory. Vertex attributes that are usually stored as 32-bit floating point numbers, such as position attribute data, can be decoded as quantized 16-bit integer values. Additionally for attributes that are unit vectors such as normals, we can decode as oct-encoded data.
When decoding on the GPU, we skip the quantization or octahedron transform operation in the Draco decoder module and instead retrieve and store any transformation constants. The smaller decoded data can be passed to the GPU where the dequantization or oct-decoding operations are performed in the shader when rendering. This results in a smaller memory footprint, both in the main application thread running on the CPU and in parallel on the GPU.
When performing dequantization in the GPU with the previously mentioned New York City 3D tileset, there is a 52% savings in memory used by the GPU with no difference in file size, no differences in visual quality, and no impact on total tileset loading time as compared to decoding entirely with the Draco decoding module.
| Draco compressed | Draco compressed with dequantization on the GPU | |
|---|---|---|
| GPU Memory | 119MB | 57MB |
| Tileset load time | 7.45 seconds | 7.44 seconds |
Using Compressed glTF Assets
Look for loading your own Draco compressed models in Cesium 1.44, and faster decoding in 1.45! Use this glTF-pipeline branch with in-progress Draco compression to apply Draco mesh compression to an existing glTF asset.
We’d love to hear more about your usage of Draco encoded 3D content. Let us know how Draco compression impacts your models by tweeting the results to us, @CesiumJS.